Getting data into Splunk can be challenging, especially when dealing with syslog, one of the most crucial data sources. Syslog can present several hard-to-solve problems, such as high volume, non-compliant messages, and the use of the unreliable UDP network protocol. One Identity’s syslog-ng Premium Edition (PE) and syslog-ng Store Box (SSB) can help manage these challenges effectively.

Why syslog-ng?
Splunk ingests data using indexers, but sending log data directly from hosts to indexers is generally considered poor practice, as it can easily overload individual indexers. While network load-balancers can distribute the load among indexers, they don’t address issues related to the content of the messages.
An alternative approach involves using syslog-ng to collect log messages, and then Splunk Universal Forwarders (UF) to send these messages to the indexers. However, this method introduces additional complexity and tends to have lower performance. In this setup, syslog-ng collects log messages, writes them into a directory structure, and Splunk UF forwards the messages to the indexers.
The most efficient and high-performance solution is to let syslog-ng handle both log collection and forwarding. Both syslog-ng Premium Edition (PE) and syslog-ng Store Box (SSB) can send log messages to the Splunk HTTP Event Collector (HEC) using their splunk-hec() destinations, with a built-in load-balancer to distribute the load among multiple indexers.
A single syslog-ng instance can manage hundreds of thousands of log messages. Additionally, this syslog-ng instance is versatile: it can archive log messages for long-term storage, filter messages to ensure only relevant data reaches Splunk, and feed multiple log analytics systems if different departments use various software.
A simple syslog-ng PE splunk-hec() configuration
Our goal is not to delve deeply into syslog-ng configuration. Below is a simple example of a syslog-ng Premium Edition (PE) configuration. This configuration collects log messages using the unreliable UDP protocol, discards some of the log messages, and finally forwards the remaining messages to Splunk.
@version: 7.0
@include "scl.conf"
source s_net {
udp-balancer(
listeners(8)
port(514));
};
destination d_splunk_hec {
splunk-hec(
index("main")
token("fcddc233-a7f4-43eb-903a-0654625c5803")
url("http://your-splunk-server:8088/services/collector/event") );
};
filter f_program { not program('proftpd');};
filter f_nodebug { level(info..emerg);};
log {
source(s_net);
filter(f_program);
filter(f_nodebug);
destination(d_splunk_hec);
};
As you can see, the configuration starts with a version declaration and the syslog-ng configuration library (a collection of configuration snippets) is included. Various configuration blocks define the source, the destination, and the filters. These configuration blocks are connected using a log statement.
Of course, the splunk-hec() destination has many more options available, as you can see in this slightly more complex configuration:
destination d_splunk_hec {
splunk-hec(
url("https://192.168.38.72:8088/services/collector/event")
index("main")
sourcetype("_json")
token("fcddc233-a7f4-43eb-903a-0654625c5803")
delimiter("\n")
time("$S_UNIXTIME.$S_MSEC")
host("$HOST")
event("$(format-json --key event --scope nv-pairs --key .SDATA.* --shift 1 .SDATA.meta.* --shift-levels 2 --scope core --key ISODATE )\n")
disk-buffer( mem-buf-length(10000) disk-buf-size(2000000) reliable(no) dir("/var/disk-buffer") )
tls(peer-verify(no))
batch-lines(100)
batch-bytes(512Kb)
batch-timeout(10000)
timeout(10));
};
You can configure the template of the message using the event() parameter a disk-buffer to hold the messages while Splunk is unavailable due to maintenance or network problems, and various batching-related options to fine tune performance. For a complete list of options and their parameters, check the documentation.
Filtering
A filter can compare macro (name-value pairs, parsed from log messages) values. This one checks for empty process ID fields.
filter f_pid {"${PID}" !=""};
There are also quite a few filter functions. This one checks if the level of the syslog message is set between “error” and “emergency”:
filter f_levels { level(err..emerg) };
Filters can also do pattern matching. The following filter checks the content of the HOST macro:
filter host_match { match('dbrsvr-\d{2,5}', value("HOST")); };
Best of all: you can combine filters using Boolean operators:
filter f_demo1 { host("example") and match("deny") value("MESSAGE")); };
This allows some very complex filtering rules, making sure that you forward all relevant log messages to Splunk, but only those. You can see filters in use in the sample configuration above.
Minimize UDP event loss
You can minimize UDP event loss using syslog-ng in several ways. One method is to use relays positioned as close to the source as possible. Another approach is to use the udp-balancer() source in syslog-ng PE.
Using relays is a best practice in any large syslog-ng deployment. But what are relays? Instead of sending logs directly to the central syslog-ng servers, you can create additional layers between the clients and the central server. Relays do not store incoming log messages; instead, they forward them to the next relay or to the central server.
Relays are particularly beneficial if you have multiple physical locations or large deployments. They ensure logs are collected even if the central server is unavailable due to network issues or maintenance. Relays can also help distribute log processing.
Relays are especially important when dealing with UDP log sources. Since UDP is unreliable, collecting logs farther from the source increases the risk of message loss. Placing relays close to UDP sources and forwarding log messages using more reliable protocols mitigates this risk.
For low-volume UDP message sources, placing a relay near the source is usually sufficient. However, for high-volume UDP message sources, you should use the udp-balancer() source in syslog-ng PE. The udp-balancer() source is not limited to a single UDP listener and can distribute incoming log messages evenly among multiple listeners.
Previously, we saw a simple configuration. Below is an example of a more complex udp-balancer() configuration:
source s_udp_bsd-514_lb {
udp-balancer(
listeners(8)
port(514)
so-rcvbuf(16777216)
log-fetch-limit(20000)
log-iw-size(30000));
};
You can find more information about the various parameters in the syslog-ng PE documentation.
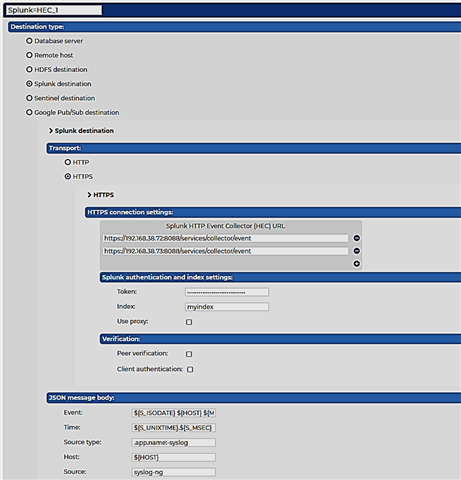
SSB splunk-hec configuration
SSB is an appliance with syslog-ng PE at its heart. SSB does not support all of the syslog-ng PE features on its web interface, but in return, it is ready to use a few minutes after you turn it on. It provides not just GUI to syslog-ng, but full log life cycle management, and lightning fast search even in terabytes of log messages.
Configuring the Splunk destination only takes a few clicks:
You also receive syslog-ng PE clients and relays when you buy SSB, so you can install relays to remote locations, and ensure low UDP event loss.
Source: https://www.syslog-ng.com/community/b/blog/posts/getting-data-to-splunk
About DT Asia
DT Asia began in 2007 with a clear mission to build the market entry for various pioneering IT security solutions from the US, Europe and Israel.
Today, DT Asia is a regional, value-added distributor of cybersecurity solutions providing cutting-edge technologies to key government organisations and top private sector clients including global banks and Fortune 500 companies. We have offices and partners around the Asia Pacific to better understand the markets and deliver localised solutions.