Trong thế giới của cơ sở dữ liệu quan hệ, dữ liệu thường được cấu trúc theo các nguyên tắc chuẩn hóa. Mục tiêu là giảm thiểu sự dư thừa và đảm bảo tính toàn vẹn của dữ liệu. Đây từ lâu đã là nền tảng của thiết kế cơ sở dữ liệu, đặc biệt khi dữ liệu được tổ chức theo Chuẩn hóa lần thứ ba (3NF) hoặc thậm chí là Chuẩn Boyce-Codd (BCNF). Tuy nhiên, khi dữ liệu được chuẩn hóa cao hơn, nó lại trở nên kém phù hợp hơn với định dạng cần thiết cho các báo cáo, dashboard và các ứng dụng phân tích kinh doanh.
Khi bạn đã kết nối với các nguồn dữ liệu, xác định được thông tin liên quan và tạo ra bộ dữ liệu của mình, bước quan trọng tiếp theo là đảm bảo tính chính xác của dữ liệu đó. Thật đáng ngạc nhiên khi phát hiện rằng bộ dữ liệu có thể chứa các lỗi sai, dữ liệu trùng lặp hoặc những gì thường được gọi là “dữ liệu bẩn”. Đây chính là lúc Toad Data Point trở thành công cụ thiết yếu đối với các nhà phân tích dữ liệu.
Trong bối cảnh ứng dụng ngày nay, phần lớn quá trình nhập dữ liệu được giao cho người dùng cuối. Dù là đăng ký tài khoản trên một trang web hay điền vào biểu mẫu trực tuyến, người dùng thường được yêu cầu cung cấp thông tin cá nhân như địa chỉ email, số điện thoại và mã bưu điện. Tuy nhiên, nhiều người chỉ nhập thông tin ngẫu nhiên hoặc không chính xác để có thể tiếp tục. Kết quả là cơ sở dữ liệu có thể nhanh chóng bị lấp đầy bởi những dữ liệu không hợp lệ, không nhất quán hoặc gây hiểu lầm.
Là một nhà phân tích dữ liệu, nhiệm vụ của bạn là phát hiện và xử lý các vấn đề này. Nhưng làm thế nào để bạn xác định được dữ liệu sai một cách nhanh chóng và hiệu quả?
Khi bạn đã tạo bộ dữ liệu trong Toad Data Point, bạn có thể gửi bộ dữ liệu đó đến mô-đun Data Profiling (Phân tích dữ liệu). Mô-đun này giúp bạn phát hiện các điểm bất thường trong bộ dữ liệu. Nó bao gồm nhiều thành phần khác nhau mà chúng ta sẽ tìm hiểu chi tiết ở phần dưới.
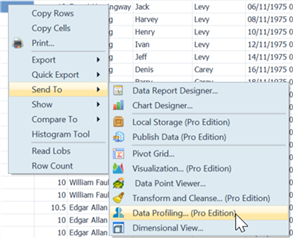
Để gửi bộ dữ liệu đến chức năng phân tích, hãy nhấp chuột phải vào kết quả của bộ dữ liệu, sau đó chọn Send To | Data Profiling:
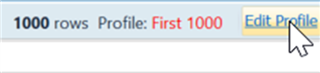
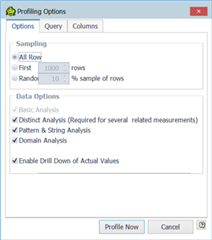
Khi Data Profiling được khởi chạy, theo mặc định, nó sẽ phân tích 1.000 dòng dữ liệu đầu tiên. Nếu bạn muốn phân tích toàn bộ bộ dữ liệu, bạn có thể thực hiện bằng cách nhấp vào Edit Profile, sau đó chọn All Rows.
Trong tab Summary, bạn sẽ thấy bản phân tích cho từng cột dữ liệu được hiển thị dưới dạng biểu đồ. Biểu đồ này, như minh họa bên dưới, rất hữu ích trong việc phát hiện các điểm bất thường. Trong ví dụ dưới đây, tôi nghĩ rằng trường OrderID là duy nhất, nhưng tôi có thể thấy rằng có những dòng bị lặp lại. Để xem các dòng bị lặp, tôi chỉ cần nhấp đúp vào phần màu cam trên thanh OrderID, các dòng bị lặp sẽ được liệt kê ra.
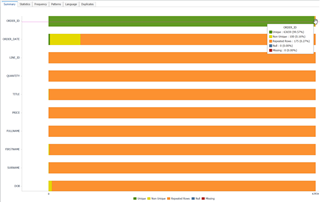
Điều này cho thấy một điểm thú vị – Order ID thực tế không phải lúc nào cũng là duy nhất. Để xác định giá trị duy nhất cho từng dòng (Khóa chính), tôi cần sử dụng kết hợp OrderID + LineID.
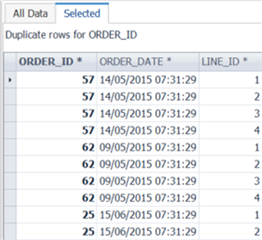
Chuyển sang tab Statistics – nếu bạn cần thông tin thống kê dữ liệu, chỉ riêng chức năng này cũng đã xứng đáng với chi phí bản quyền. Chỉ cần chọn cột bên khung bên trái, bạn sẽ ngay lập tức nhận được phân tích thống kê như: trung vị, giá trị lớn nhất, nhỏ nhất, giá trị trung bình, mode, tổng, độ lệch chuẩn, v.v. Bạn cũng có thể dễ dàng hiển thị biểu đồ Phân bố giá trị và Phân vị (Percentiles) cho từng cột. Theo quan điểm cá nhân của tôi, mức độ chi tiết mà tab này cung cấp thực sự rất ấn tượng. Nó giúp tiết kiệm đáng kể thời gian so với việc phải tự tính toán các giá trị này bằng tay.
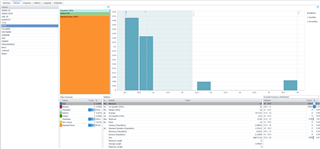
Tab tiếp theo mà tôi muốn nhấn mạnh là Patterns. Đúng như tên gọi, tab này phân tích các mẫu trong các cột dạng văn bản/chuỗi trong bộ dữ liệu. Rất nhiều khách hàng sử dụng tính năng này cho các cột có định dạng rõ ràng như địa chỉ email, mã bưu điện, số điện thoại.
Tính năng này sẽ hiển thị Word Pattern (kiểm tra xem dữ liệu có chứa chữ cái, số, dấu câu, khoảng trắng hay không) và Letter Pattern (thứ tự xuất hiện của các chữ cái, số, dấu câu, khoảng trắng).
Trong ví dụ dưới đây, công cụ đã nhanh chóng phát hiện các bất thường trong trường địa chỉ email — cụ thể là có những email chứa khoảng trắng, điều này khiến chúng trở thành địa chỉ không hợp lệ.
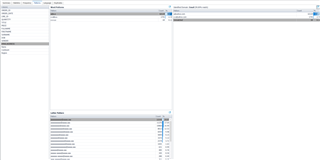
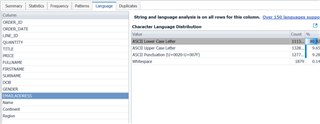
Tab Language cung cấp thông tin tương tự như tab Pattern, nhưng lần này tập trung vào việc phân tích phân bố ký tự được sử dụng trong các cột dạng văn bản/chuỗi. Một lần nữa, trường địa chỉ email hiển thị có chứa khoảng trắng trong dữ liệu.
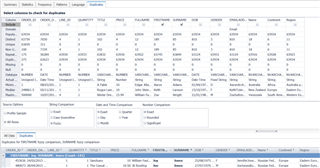
Cuối cùng, tab Duplicates cho phép bạn tìm kiếm các dòng dữ liệu trùng lặp trong bộ dữ liệu. Bạn chỉ cần chọn các cột muốn kiểm tra, và công cụ sẽ tìm các dòng trùng lặp dựa trên tất cả các cột được chọn. Trong ví dụ bên dưới, tôi đang tìm các trường Firstname và Surname bị trùng. Vì đây là các cột dạng chuỗi (string), tôi chọn phương thức tìm kiếm fuzzy. Điều này cho phép Toad tìm các tên tương tự nhau, bao gồm cả các lỗi chính tả có thể xảy ra khi nhập liệu. Ảnh minh họa bên dưới cho thấy “Joy Jones” và “Joe Jones” được đánh dấu là trùng lặp dạng fuzzy vì chỉ có 1 ký tự khác biệt trong tên đầy đủ. Tuy nhiên, tôi biết rằng đây không phải là bản sao trùng lặp, vì vậy tôi sẽ thêm một số cột khác để làm cho việc tìm kiếm chính xác hơn.
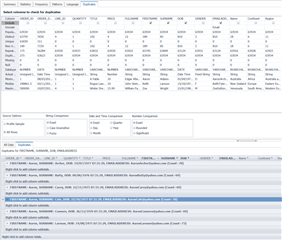
Ở ví dụ dưới đây, tôi đã thêm các cột Ngày sinh và Địa chỉ email, vì tôi tin rằng hai thông tin này sẽ giúp xác định một cá nhân duy nhất.
Sau khi đã phân tích bộ dữ liệu, xác định các điểm bất thường cần được xử lý trong ứng dụng nguồn và/hoặc điều chỉnh lại truy vấn của mình, giờ đây tôi có thể yên tâm tiếp tục công việc vì dữ liệu mà tôi truy xuất đã đảm bảo độ chính xác.
Về DT Asia
DT Asia được thành lập năm 2007 với sứ mệnh đưa các giải pháp bảo mật CNTT tiên phong khác nhau từ Hoa Kỳ, Châu Âu và Israel gia nhập thị trường.
Hiện tại, DT Asia đã là một nhà phân phối giá trị gia tăng trong khu vực đối với các giải pháp an ninh mạng, cung cấp công nghệ tiên tiến cho các tổ chức chính phủ trọng yếu cũng như các khách hàng tư nhân lớn bao gồm các ngân hàng toàn cầu và các công ty trong danh sách Fortune 500. Với các văn phòng và đối tác rộng khắp trong khu vực Châu Á Thái Bình Dương, chúng tôi hiểu rõ hơn về thị trường và từ đó mang đến những giải pháp bản địa hóa phù hợp với từng quốc gia, từng tổ chức.
Cách chúng tôi giúp bạn
Nếu bạn muốn biết thêm Toad Data Point: Làm thế nào để kiểm tra độ chính xác của dữ liệu, bạn đang ở đúng nơi, chúng tôi sẵn sàng giúp đỡ! DT Asia là nhà phân phối của Quest Software, đặc biệt tại Việt Nam và châu Á, các kỹ thuật viên của chúng tôi có kinh nghiệm sâu rộng về sản phẩm và các công nghệ liên quan mà bạn luôn có thể tin tưởng. Chúng tôi cung cấp các giải pháp trọn gói cho sản phẩm này, bao gồm tư vấn, triển khai và dịch vụ bảo trì.
Để biết thêm thông tin chi tiết và được hỗ trợ, vui lòng truy cập: https://dtasiagroup.com/quest/